업무상 JDBC를 다뤄야 할 일이 많아졌다. JDBC는 Oracle OCI 라이브러리에 비하면 사용하기가 상당히 편한 것이 사실이다. 하지만 Char/Varchar/Nchar/Clob/Nclob과 같은 Character 타입에 저장된 한글 데이터를 다루는 과정에서 약간의 우여 곡절이 있어서 그것을 여기에 정리하고자 한다.
우선, JDBC를 사용하여 Character 타입의 데이터를 조회 하기 위해서는 ResultSet의 getString, getCharacterStream, getBytes와 같은 API를 사용하여야 한다. JDBC는 자바가 유니코드를 다루기 때문에 Oracle DBMS로 부터 JDBC를 통해서 데이터를 조회하는 과정에서 UTF-8/UTF-16으로 데이터를 변환한다.
데이터에 대한 변환 과정은 아래의 링크를 참조하자.
[참조 1]
http://codemuri.tistory.com/43
[참조 2]
The techniques that the Oracle JDBC drivers use to perform character set conversion for Java applications depend on the character set the database uses. The simplest case is where the database uses the US7ASCII or WE8ISO8859P1 character set. In this case, the driver converts the data directly from the database character set to UTF-16, which is used in Java applications, and vice versa.
If you are working with databases that employ a non-US7ASCII or non-WE8ISO8859P1 character set (for example, JA16SJIS or KO16KSC5601), then the driver converts the data first to UTF-8 (this step does not apply to the server-side internal driver), then to UTF-16. For example, the driver always converts CHAR and VARCHAR2 data in a non-US7ASCII, non-WE8ISO8859P1 character set. It does not convert RAW data.
출처) https://docs.oracle.com/cd/A97630_01/java.920/a96654/advanc.htm
일반적으로 JDBC를 사용하여 Oracle에 저장된 Character 타입의 데이터를 조회하는데 기존에 제공되는 API를 사용할 경우 별 문제가 발생하지 않는다. 하지만, Third Party Tool(Orange, Toad, 등..)을 사용할 경우, 사용자는 데이터 베이스의 캐릭터 셋을 고려하지 않고, 해당 프로그램의 기본 설정대로 텍스트를 저장하고 조회할 수 있다. 이 경우에, Third Party 툴은 Database의 캐릭터셋과 상관없는 캐릭터 셋으로 데이터를 저장할 수 있다. 이는 물론 Sqlplus와 같은 기본 툴을 사용하더라도 발생할 수 있는 문제이다. 예를 들면 아래와 같이 Character 타입의 데이터를 저장 가능하다.
[데이터 저장 및 조회 환경]
Putty(UTF-8) → sqlplus (NLS_LANG=MSWIN949) → Oracle(NLS_CHARACTERSET=MSWIN949)
위와 같은 환경으로 한글 데이터를 저장할 경우, 실제 UTF-8로 인코딩 된 데이터가 Oracle의 Character Type 컬럼에 저장된다. NLS_LANG과 NLS_CHARACTERSET이 동일하기 때문에 사용자가 저장하는 데이터에 대해서 Oracle이 별도의 데이터 Conversion을 수행하지 않기 때문에 가능하다. 위와 같이 사용하는 사람이 과연 존재 할까? 존재한다. 여러 회사를 보았다.
[SSH 터미널 인코딩]

[NLS LANG 설정]

[데이터 삽입 및 조회]
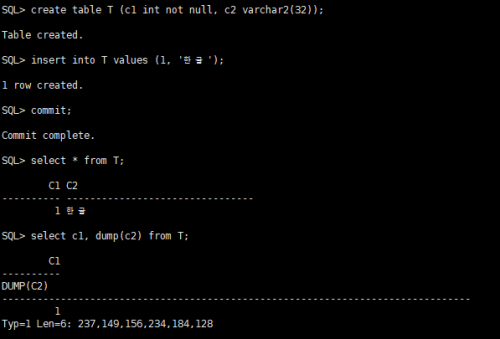
위의 [데이터 삽입 및 조회]에서, DUMP(C2)의 결과를 보면 알겠지만, “한글” 값에 대한 UTF-8 인코딩 결과가 저장된 것은 알 수 있다.
자, 그럼 위와 같은 데이터를 JDBC에서 조회할 경우 어떤 일이 발생할까? 아래에서 조회 결과를 확인 할 수 있다.
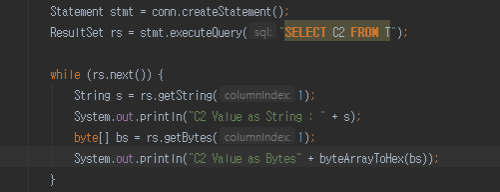
[데이터 조회 소스 코드]
[데이터 조회 결과]
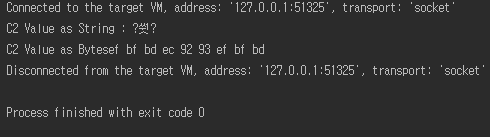
C2 컬럼 데이터인 “한글”이 정상적으로 출력되기를 기대했던 사람이 있는가? 결과에서 볼 수 있듯이, 전혀 그렇지 않다. getBytes로 가져온 값 자체도 sqlplus로 조회한 DUMP(C2) 값과 전혀 다른것을 알 수 있다. 왜 이런 결과가 나온것인가~? 다들 예상했고 위에서도 언급했지만 ,이는 JDBC에서 Character 타입의 데이터를 조회할 때 C2 컬럼의 값이 MSWIN949 인코딩으로 인지하고 이를 JDBC를 통해서 자바 클라이언트까지 전달하는 과정에서 UTF-8/UTF-16 변환을 수행했기 때문에 발생한 결과이다.
(“?쒓?”에서 처음과 끝의 “?”가 출력 되는 이유는 MSWIN949에서 UTF-8로 변환하는 과정에서 해당 코드 포인트에 매치되는 값이 없기 때문에 내부적으로 “?”로 변환 된것이다.)
저자는 위와 같은 상황에서 “한글” 데이터를 정상적으로 출력 하거나, 혹은 Dump(C2)와 동일한 형태의 byte 배열의 값이 필요한 상황이다. 물론, 성능적으로도 최대한의 부하를 줄여서 조회를 해야 한다. 가능한 대안은 아래와 같다.
방법 1. RAWTOHEX 매크로 사용
- VARCHAR2의 값을 HEX로 출력한다. 즉 DUMP(C2)와 동일한 형태의 값을 String으로 받을 수 있다.
- 위의 매크로를 사용하여 데이터를 조회할 경우, getString 결과인 String의 값을 parsing하여 byte array에 저장하고 이를 다시new String(bytearray, “UTF-8”) 형태로 변환 해야한다.
방법 2. CONVERT 매크로 사용
- CONVERT(C2, ‘KO16MSWIN949′, ‘UTF8′) 매크로를 사용한다.
- Oracle에서 UTF8을 MS949로 컨버팅 하여서 전달한다. DB에서 데이터 컨버전과 관련된 부하가 발생한다.
방법 3. ANYDATA.CONVERTVARCHAR2 매크로 사용
- ANYDATA.CONVERTVARCHAR2(C2)로 조회할 경우, Oracle JDBC의 AnyData 데이터 타입이 리턴되며, 해당 데이터 내부에 DUMP(C2)와 동일한값을 지는 바이트 배열을 포함한다.
- 위의 매크로 사용시, AnyData의 데이터 배열을 new String(bytearray, “UTF-8”) 형태로 변환 해야한다.
- DB에서 컨버전 하는 것이 아니라 클라이언트 단에서 수행하므로, 클라이언트에서 부하가 발생한다.
'Database > Client Side' 카테고리의 다른 글
| JDBC DatabaseMetadata 기반 정보 조회 / 스키마, 테이블, 컬럼, PK, Index / 오라클, MySQL, PostgreSQL, SQL Server, ... (0) | 2020.06.15 |
|---|---|
| MySQL의 캐릭터셋 인코딩 이해하기 (2) | 2018.01.17 |
댓글